
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Bayesian
- DataAnalyst
- chatGPT
- 인과추론 무작위 실험
- 벡터
- SQL
- 잠재적결과
- CausalInference
- 글또10기
- mathematicalthinking
- 독후감
- 티스토리챌린지
- recommendation system
- 인과추론
- 실무로통하는인과추론
- 코세라
- 데이터 분석
- 수학적해석학
- 베이지안통계
- 선형대수학
- 인과추론개요
- Recsys
- 데이터분석가
- 나의서양미술순례
- 오블완
- BigQuery
- 네카라쿠배당토
- 빅쿼리
- 데이터분석가 코딩테스트
- 데이터분석
- Today
- Total
Derek 의 데이터 분석 성장기
[실무로 통하는 인과추론] 4. 편향보정 본문

해당 글의 내용과 코드는 모두 실무로 통화는 인과추론을 참고하였습니다.
1. 개요
A/B Test 이외의 인과추정 효과를 위한 편향 제거 방법에는 선형회귀 분석, 성향점수 가중치가 존재한다. 특히, 회귀분석은 단순 통계 혹은 머신러닝 그 이상으로, 인과추론의 핵심으로서도 가장 많이 이용된다고 한다. 이는 DID(이중차분법), 이원고정효과(TWFE), 이중/편향 제거(dobule/debiased), 그리고 도구변수나 불연속 설계등에서도 사용된다.
그리고, 처치가 무적위 배정된 것처럼 이전에 배운 보정 공식을 활용(=X 를 다른 변수로 활용하는 것) 예를 들어, 대출 금액에 따른 채무 불이행을 파악하고 싶을때, 다른 변수 X(신용한도) 를 활용한다고 할때, 연속형 변수이기 때문에 이는 그룹화 하기 어려운 문제로 변질될 수 있음.
그리고, 인과추론에서는 일반 회귀모델과 같은 의미이지만 다른 표현을 사용하는데
* 특성(=공변량 또는 독립변수)
* 가중치(=매개변수 또는 계수)
* 목표(결과 또는 종속변수) 로 표현됨.
또한, 회귀모델의 문제인 차원의저주(변수가 너무 많아서 성능이 낮아져)를 벗어나기 위해 잠재적 결과를 선형회귀 같은 방식으로 모델링할 수 있다고 가정하고, X로 정의된 각각의 셀(그룹)을 내삽하고 외삽하는 것으로 해결한다고 합니다.
이 알고리즘은 결과변수를 X 변수로 투영하고, 투영값으로 실험군과 대조군을 비교한다고 합니다.
2. 회귀분석

import statsmodels.formula.api as smf
result = smf.ols('watch_time ~ C(recommender)', data=data).fit()
result.summary().tables[1]
위와 같은 추천시스템에 따른 watch_time 시청 시간의 결과차이를 A/B Test 를 회귀모델로 분석한 것 입니다.
Watchtime_i = B_0 + B_1 * Challenger_i + e_i 회귀식을 생각하시면 되겠습니다.
challenger 의 1과 0은 추천시스템 적용여부입니다. 절편(intercept) 은 모델 앞 B_i 로(=추천 시스템의 이전버전과 새로운 버전의 추정값)를 표현하는 것 입니다.
즉, 이 절편은 이전 버전의 추천 시스템 사용 고객의 예상 시천 시간(2.04)시간을 의미하는 것 입니다. 그리고, 새로운 버전을 이용한 고객의 AtE는 0.14 시간 늘어난 값입니다.
(data
.groupby("recommender")
["watch_time"]
.mean())
위와 같이 회귀모델이 아닌, 원본 데이터의 평균 시청 시간의 차이와도 동일합니다. 회귀식이에서는 Hat(B_1) - Hat(B_0) 두 그룹의 평균차이와 동일합니다. 그럼, 회귀 분석은 그냥 데이터 평균차이와 동일한데 왜 사용할까요?
2-2. 회귀분석을 통한 보정

다시, 신용한도(credit_limit)가 채무 불이행률(Default) 에 미치는 영향을 추정하는 상황으로 돌아가보겠습니다.
수식으론 Default_i = B_0 + B_1 * line_i + e_i 입니다.
model = smf.ols('default ~ credit_limit', data=risk_data).fit()
model.summary().tables[1]

위 결과는 교란으로 인해 채무불이행률과 신용 한도가 음의 상관관계가 되었습니다. 신용한도별 평균채무불이행률로 인한, 음의 추세가 명확한 결과입니다. 은행은 신용한도가 높은 사람들에게 대출을 빌려주고, 채무불이행률(default)가 낮기 때문이죠. 이 편향을 보정하기 위해선, 이론적으로 모든 교랸 요인에 따라
1) 데이터를 나누고, 2) 나눈 각 그룹 내에서 채무 불이행률을 신용한도에 회귀, 3) 기울기 매개 변수 추출을 통해 결과의 평균을 구해야 한다고 합니다. 그러나, 차원의 저주인(두 가지 신용점수 데이터)을 고려하여 그룹핑시 표본이 하나뿐인 셀만 존재하고, 해당 표본으론 회귀모델을 사용할 수 없다고 합니다.

위와 같은 데이터가 두 그룹을 동질하게 묶어주기 위한 우리가 나눈(셀 혹은 그룹) 이지만 충분한 데이터가 없습니다. 그러나 회귀 분석으로 이 상황을 해결할 수 있습니다. 교란 요인을 직접 보정하는 대신, OLS로 추정할 모델에 교란 요인을 추가하는 것 입니다.
1. Default_i = B_0 + B_1 * line_i + e_i 수식에서 -> Default_i = B_0 + B_1 * line_i + (Theta + X_i ) + e_i 로 변경합니다.
여기서 X는 교란 요인의 벡터이고, Theta는 해당 교란 요인과 관련된 매개변수의 벡터입니다. Theta가 B_1과 같지만 다르게 표현된 이유는 이 변수는 편향되지 않은 B_1 의 추정값을 얻는데 도움되기 때문이라고 하네요.
Theta 는 특별하지 않고, B_1과 똑같이 작동합니다. 이 매개변수는 장애모수라고 부른다고 하네요.
궁극적으로, 신용한도 예제에서는 신용점수(credit_1, credit_2) 와 임금(wage) 을 교란요인으로 모델에 추가할 수 있습니다. 결과는
formula = 'default ~ credit_limit + wage+credit_score1+credit_score2'
model = smf.ols(formula, data=risk_data).fit()
model.summary().tables[1]

그리고, 위의 결과는 이전 credit_limit 이 음의 계수를 갖는것과는 전혀 다른 결과를 갖게 되죠. 결과 해석도 중요합니다. 두번째 결과는 매우 작은 B_1 추정값이지만, 신용한도는 1000단위이며 채무 불이행 여부는 0또는 1이기 때문에 신용한도 1에 따른 채무 불이행률이 증가하는 정도는 아주 작기 때문입니다. 하지만, 이는 통계적으로 유의미하며 신용한도를 늘릴수록 채무 불이행률이 증가함을 알려줍니다. 교란 요인을 통제함으로서, 결과가 직관에 맞게 보다 반영되었습니다.
2-3. 회귀분석 이론
그리고, 단순선형회귀를 인과추론 식으로 표현하면 아래와 같습니다 (GPT 발 참조)

이 회귀분석은 결국 처치와 결과가 어떻게 함께 움직이는지를 분자의 공분산으로 표현하고, 처치 대상에 따라 조정하는 식 입니다. 그리고, 이 매개변수는 처치와 결과에 대한 공분산을 처치의 분산으로 나눔으로써 그 결과를 얻습니다. 그리고, 다중선형회귀 식도 이와 같지만,
다중 회귀 분석의 회귀계수는 모델의 다른 변수들의 효과를 고려한 후, 얻은 동일 설명변수의 이변량(bivariate) 계수라는 의미라고 합니다. 인과추론 관점에서 t는 다른 모든 변수를 활용해 T를 예측한 후 얻은 T의 이변량 계수라고 하고요.
3. 프리슈-워-로벨(FWL) 정교와 직교화
FWL 스타일 직교화는 가장 먼저 사용할 수 있는 편향제거 기법입니다. 처치가 무작위 배정된 것처럼 보이는데 목적이 있습니다.
위와 같은 결과시 FWL 정리에 따르면 추정 결과를 다음과 같이 세 단계로 나눈다고 합니다.
1. 편향 제거 단계 : 처치 T를 교란 요인 X에 회귀하여 처치 잔차 T tilde(~) = T - T hat(^) 를 구한다.
2. 잡음 제거 단계 : 결과 Y를 교란 요인 X에 대해 회귀하여 결과 잔차 Y tilde = Y - Y hat 를 구한다.
3. 결과 모델 단계 : 결과 잔차 Y tilde 를 처치 잔차 T tilde 에 대해 회귀하여 T가 Y에 미치는 인과효과 추정값을 구한다.
결과적으로 이는 다중선형회귀 분석을 다시 한번 더 설명 한 것이고 본질적으로 FWL의 이 추정은 회귀모델과 같다고 합니다.
3-1. 편향제거 단계
FWL에 따르면, 교란요인으로부터 처치 신용한도를 예측하는 회귀 모델을 적합시켜 데이터 편향을 제거할 수 있습니다.
plt_df = (risk_data
.assign(size=1)
.groupby("credit_limit")
.agg({"default": "mean", "size":sum})
.reset_index())
plt.figure(figsize=(10,4))
sns.scatterplot(data=plt_df,
x="credit_limit",
y="default",
size="size",
sizes=(1,100))
plt.title("Default Rate by Credit Limit")
#회귀모델
debiasing_model = smf.ols(
'credit_limit ~ wage + credit_score1 + credit_score2',
data=risk_data
).fit()
#잔차와 평균을 합함
risk_data_deb = risk_data.assign(
# for visualization, avg(T) is added to the residuals
credit_limit_res=(debiasing_model.resid
+ risk_data["credit_limit"].mean())
)
default를 편향 제거된(잔차화된) 처치인 Line tilde에 회귀하면, 편향 제거 모델에 사용된 교란 요인을 통제하면서 신용 한도가 채무 불이행률에 미치는 영향을 파악할 수 있습니다.
model_w_deb_data = smf.ols('default ~ credit_limit_res',
data=risk_data_deb).fit()
model_w_deb_data.summary().tables[1]
위 코드는 잔차가 평균의 합을 가지고 한번더 회귀모델을 학습시킨 것 입니다. 이를 통해 편향을 제거한 것이죠. 편향제거를 통해 모든 교란 요인이 편향 제거에 포함 되어, 신용한도가 채무불이행률에 미치는 인과적 영향에 대해 편향되지 않은 추정 값(unbiased estimate)을 얻을 수 있다고 합니다.
plt_df = (risk_data_deb
.assign(size=1)
.assign(credit_limit_res = lambda d: d["credit_limit_res"].round(-2))
.groupby("credit_limit_res")
.agg({"default": "mean", "size":sum})
.query("size>30")
.reset_index())
plt.figure(figsize=(10,4))
sns.scatterplot(data=plt_df,
x="credit_limit_res",
y="default",
size="size",
sizes=(1,100))
plt.title("Default Rate by Debiased Credit Limit")
편향 제거 된 결과는 이전 편향된 결과와 달리, 두 변수사이의 상관관계를 가지지 않습니다.
3-2. 잡음 제거 단계
잡음 제거 단계는 분산을 줄이는 효과를 가질 수 있습니다. 해당 코드를 기준으론 default 은 채무 불이행률 잔차에 평균을 더한 값과 같습니다.
denoising_model = smf.ols(
'default ~ wage + credit_score1 + credit_score2',
data=risk_data_deb
).fit()
risk_data_denoise = risk_data_deb.assign(
default_res=denoising_model.resid + risk_data_deb["default"].mean()
)
3-3. 최종 결과 모델
FWL 정리의 마지막 단계인 결과 모델에서는 두 잔차 Y tilde 와 T tilde를 이용해서 단순히 Y Tilde 를 T Tilde에 대해 회귀하면 됩니다.
model_se = smf.ols(
'default ~ wage + credit_score1 + credit_score2',
data=risk_data
).fit()
print("SE regression:", model_se.bse["wage"])
model_wage_aux = smf.ols(
'wage ~ credit_score1 + credit_score2',
data=risk_data
).fit()
# subtract the degrees of freedom - 4 model parameters - from N.
se_formula = (np.std(model_se.resid)
/(np.std(model_wage_aux.resid)*np.sqrt(len(risk_data)-4)))
print("SE formula: ", se_formula)* 위 코드는 표준오차를 보는 코드입니다.
* 결과 : 결국 잔차를 가지고, default_rest 를 예측하는 모델입니다.
model_w_orthogonal = smf.ols('default_res ~ credit_limit_res',
data=risk_data_denoise).fit()
model_w_orthogonal.summary().tables[1]
편향 제거 단계에서 얻은 매개변수 추정값은 신용한도와 다른 모든 공변량을 사용해, 회귀했을때와 동일합니다. 표준오차와 p 값도 모든 변수를 포함하여 처음 모델을 사용했을 때와 같은것. 이것이 잡음 제거 단계의 효과입니다.

* 편향제거 신용한도에 따른 잡음 제거된 채무불이행률
3-4. FWL 요약

위 결과를 보자면, 신용한도의 편향제거를 제거하고, 잡음이 제거된 채무불이행률로 T와 Y의 관계를 파악했습니다.
아래의 단계는 위의 FWL 단계입니다.
1. 편향 제거 단계 : 처치 T를 교란 요인 X에 회귀하여 처치 잔차 T tilde(~) = T - T hat(^) 를 구한다.
2. 잡음 제거 단계 : 결과 Y를 교란 요인 X에 대해 회귀하여 결과 잔차 Y tilde = Y - Y hat 를 구한다.
3. 결과 모델 단계 : 결과 잔차 Y tilde 를 처치 잔차 T tilde 에 대해 회귀하여 T가 Y에 미치는 인과효과 추정값을 구한다.
3-5. 오목성 제거 및 처치 선형화

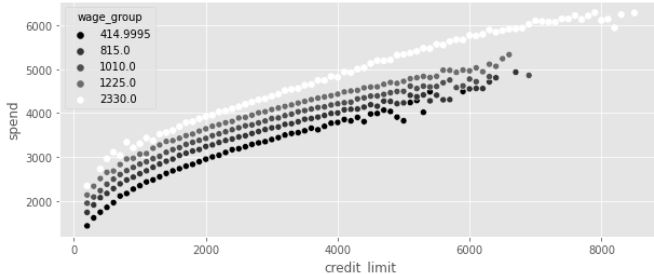
소비그룹에 따른 신용한도와 소비 데이터를 보았을때, 오목성이 존재한다. 신용한도가 높아짐에 따라 소비의 증가 기울기 곡선이 낮아진다는 의미이다

plt_df = (spend_data
# apply the sqrt function to the treatment
.assign(credit_limit_sqrt = np.sqrt(spend_data["credit_limit"]))
# create 5 wage binds for better vizualization
.assign(wage_group = pd.IntervalIndex(pd.qcut(spend_data["wage"], 5)).mid)
.groupby(["wage_group", "credit_limit_sqrt"])
[["spend"]]
.mean()
.reset_index())
plt.figure(figsize=(10,4))
sns.scatterplot(data=plt_df,
x="credit_limit_sqrt",
y="spend",
palette="gray",
hue="wage_group")
model_spend = smf.ols(
'spend ~ np.sqrt(credit_limit)',data=spend_data
).fit()
model_spend.summary().tables[1]
이 문제를 해결하기 위해, 처치(Credit Limit) 와 결과를 선형 관계로 변화해야 한다. 제곱근 함수 또는 신용 한도를 분수의 거듭 제곱으로 취하는 함수를 사용해, 처치 선형화를 구현한다. 이는 선형회귀 모델(인과추론)을 적용하기 위해 모델의 파라미터를 변형시켜주는 과정이다.
찾고 싶은 인과 매개변수는 np.sqrt(credit_limit) 이다. 해당 모델은 신용한도가 소비에 미치는 영향도를 알기 위한 그래프이자 모델이다. 그러나 아직 임금이 신용한도와 소비 사이에 교란 요인으로 작용하고 있다.

이와 같이, 이전 모델의 예측값(기울기 선)이 원본 데이터 그래프를 함께 비교하면, 기울기가 상향 편향되어 있음을 알 수 있다. 이는 임금이 높아지면 소비와 신용한도 모두가 증가하기 때문이다. 즉 교란변수가 영향을 함께 준 것 이다.
이를 해결하기 위해
model_spend = smf.ols('spend ~ np.sqrt(credit_limit)+wage',
data=spend_data).fit()
model_spend.summary().tables[1]
신용한도 제곱근에 + wage(임금)을 포함하여, 임금 수준이 소비에 미치는 영향의 편향 되지 않은 추정값을 얻을 수 있다. 모델에 임금을 포함하여 상향 편향을 보정했기 때문이다.

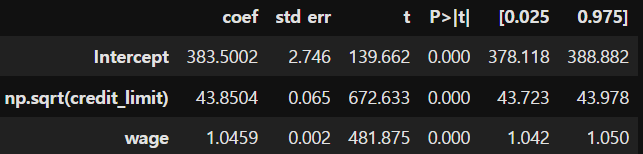
3-6. 비선형 FWL과 편향 제거
비선형 데이터에 FWL을 정리하는 적용방법은 먼저 비선형을 처리해야 합니다.
1. 처치 선형화 단계 : T와 Y의 관계를 선형화하는 함수 F를 찾는다.
2. 편향 제거 단계 : F(T)를 교랸 요인 X에 회귀하고 처치 잔차 Tilde F(T) = F(T) - Hat F(T) 를 구한다.
3. 잡음 제거 단계 : 결과 Y를 교란 요인 X에 회귀하고 결과 잔차 Tilde Y = Y - Hat(Y) 를 구한다.
4. 결과 모델 단계 : 이렇게 얻은 결과 모델은 결과 잔차 Tide Y를 처치 잔차 Tilde F(T)에 회귀하여, F(T) 가 Y에 미치는 인과효과의 추정 값을 구한다.
위의 신용한도와 소비 사례에서 F는 제곱근 함수이다. 따라서 비선형을 고려하여 FWL 정리를 적용하는 방법은 아래와 같다.
debias_spend_model = smf.ols(f'np.sqrt(credit_limit) ~ wage',
data=spend_data).fit()
denoise_spend_model = smf.ols(f'spend ~ wage', data=spend_data).fit()
credit_limit_sqrt_deb = (debias_spend_model.resid
+ np.sqrt(spend_data["credit_limit"]).mean())
spend_den = denoise_spend_model.resid + spend_data["spend"].mean()
spend_data_deb = (spend_data
.assign(credit_limit_sqrt_deb = credit_limit_sqrt_deb,
spend_den = spend_den))
final_model = smf.ols(f'spend_den ~ credit_limit_sqrt_deb',
data=spend_data_deb).fit()
final_model.summary().tables[1]
여기서 얻은 B_1 추정값은 앞서 교란요인인 임금과 처치를 모두 포함한 완전 모델을 실행하여 얻은 추정값과 완전히 동일하다.
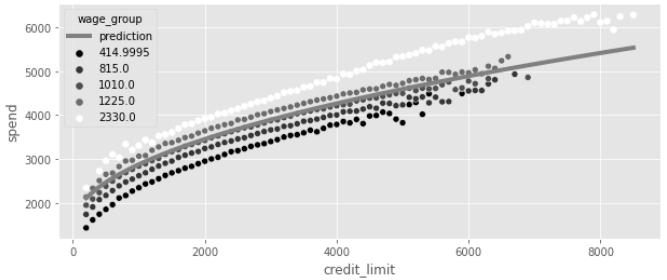
이와 같이 예측값이 상향 편향되지 않다.
'Data > 인과추론' 카테고리의 다른 글
| [실무로 통하는 인과추론] 6. 이질적 처치 효과 (1) | 2024.11.17 |
|---|---|
| [실무로 통하는 인과추론] 5. 성향점수 (0) | 2024.11.10 |
| [실무로 통하는 인과추론] 3. 그래프 인과모델 (0) | 2024.10.27 |
| [실무로 통하는 인과추론] 2장. 무작위 실험과 가설검정 (0) | 2024.10.20 |
| [실무로 통하는 인과추론] 1장 : 인과추론 소개 (4) | 2024.10.09 |



