
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Recsys
- mathematicalthinking
- 빅쿼리
- SQL
- 인과추론 무작위 실험
- 데이터분석가
- CausalInference
- DataAnalyst
- 인과추론개요
- 데이터 분석
- 나의서양미술순례
- 오블완
- chatGPT
- 글또10기
- 선형대수학
- 네카라쿠배당토
- 데이터분석가 코딩테스트
- 실무로통하는인과추론
- BigQuery
- 벡터
- 코세라
- recommendation system
- 티스토리챌린지
- 잠재적결과
- Bayesian
- 독후감
- 베이지안통계
- 데이터분석
- 인과추론
- 수학적해석학
- Today
- Total
Derek 의 데이터 분석 성장기
[베이지안] Posterior(사후확률) 업데이트 및 Distribution(분포) 본문
베이지안에서 사후확률은 사전확률과 관측(증거) 와 가능도를 기반으로 확률이 업데이트 된다.
사전확률 * Likelihood(가능도)를 곱하고 정규화한 값으로 나누었을 때, 사후확률을 업데이트 할 수 있다.
예를 들어, 101개의 쿠키 그릇이 있다고 가정해보자.
그리고, 각 그릇 번호마다 바닐라 쿠키가 들어있는 % 이다.
EX) 그릇 0 에는 바닐라 쿠키가 0% 있다.
EX1) 그릇1에는 바닐라 쿠키가 1% 있다.
EXn) 그릇n 에는 바닐라 쿠키가 n% 있다.
EX100) 그릇100에는 바닐라 쿠키가 100% 있다.
여기서 그릇을 임의로 골라 쿠키를 골랐을때, 이 쿠키가 바닐라 쿠키였다. 이때 각 값 x에 대해 그릇 x에서 쿠키가 나왔을 확률은 얼마일까?
그리고, 이는 쿠키를 101개의 그릇에서 꺼냈기 때문에 확률은 0.009901 로 동일(Uniform) 하다. 사전확률이다.
하지만, 가능도는 각 그릇에 있는 바닐라 쿠키의 비율이 다르기 때문에, 값은 다르다. EX) 그릇0에는 바닐라 쿠키가 나올 확률 0%이나, 그릇100에서 바닐라 쿠키가 나올 확률은 100% 로 관측(증거)가 다르다.
아래 그림은 바닐라 쿠키를 하나 뽑은 후의 사전확률 분포와 사후확률 분포를 나타낸다.

보는 것과 같이, 선형적으로 바닐라 쿠키가 나올 확률이 다르다. 그렇다면, 집은 쿠키를 다시 돌려놓고 동일한 그릇에서 한번 더 뽑았을 때 또 바닐라 쿠키가 나왔다고 해보자. 두번째 쿠키에 대한 사후확률이 업데이트 된 결과는 어떨까?

두 개의 바닐라 쿠키를 확인한 후, 가장 큰 번호의 그릇에서 바닐라 쿠키가 가장 많으므로, 이 그릇의 사후확률이 가장 크며, 번호가 적을 수록 바닐라 쿠키의 비율이 낮기 때문에, 두번째 시행에서 바닐라 쿠키가 나올 확률이 점점 더 줄어드는 것을 알 수 있다.
만약! 쿠키를 다시 뽑았을 때, 초콜릿 쿠키가 나왔다면 바닐라 쿠키가 2번 나오고 1번 초콜릿 쿠키가 나올 확률은 어떻게 업데이트 되었을까?
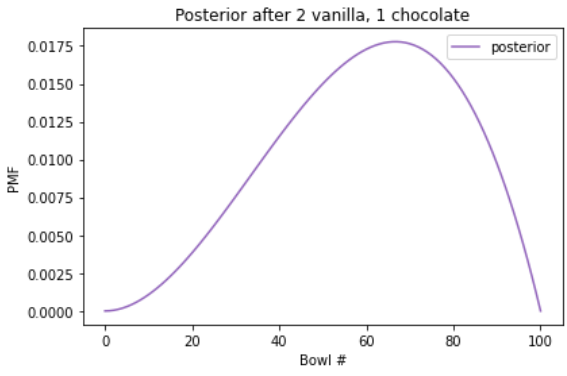
100번째 그릇은 초콜릿 쿠키가 없기 때문에 0% 이다. 그러나, 67번 정도의 그릇은 바닐라 쿠키가 67개이고 초콜릿 쿠키가 3개 정도의 비율을 가지고 있는 그릇이다. 이 그릇의 바닐라 쿠키 비율은 2/3 이다.
그래프를 보면, 사후확률분포의 꼭대기는 그릇 67번인데, 사후확률 분포에서 가장 큰 확률값은 MAP(Maximum a posteior probability) MAP 를 의미한다. 즉, 해당 확률 분포에서 해당 가설과 사건을 가장 높은 확률로 관측할 수 있는 가설(사건) 이란 의미로 해석할 수 있다.
추가적으로, 베이지안 확률을 업데이트 하기 위한 주사위 문제를 파이썬 코드로 풀어보자.
1. 6면, 8면, 12면체 주사위가 든 상자가 있다. 이 중 주사위 하나를 임의로 집어서 굴렸더니 1이 나왔다. 이 경우 육면체 주사위를 골랐을 확률은 어떻게 될까?
from empiricaldist import Pmf
# Pmf 는 확률질량함수를 나타내는 라이브러리이다.
hypos = [6, 8, 12]
prior = Pmf(1/3, hypos)
prior
#각 주사위가 선택 될 사전확률은 0.33333 이다.
likelihood1 = 1/6, 1/8, 1/12
#가능도는 각 주사위에서 1이 나올 확률이다. 6면체 주사위는 1/6 확률로 1이 나온다.
posterior = prior * likelihood1
posterior.normalize()
posterior
# 사후확률은 사전 * 가능도를 한 후, 정규화 한 값이다. 정규화는 값의 합을 1로 만들어주는 것 이다.
# 육면체 주사위의 사후확률은 4/9 이다.
# 이번에는 동일한 주사위를 굴려, 7이란 숫자가 나왔다. 이때의 가능도는 다음과 같다.
# 설명 : 육면체 주사위에서는 7이 나올 수 없으므로, 가능도는 0이다. 다른 주사위의 확률은 동일.
likelihood2 = 0, 1/8, 1/12
#사후 확률 업데이트
posterior *= likelihood2
posterior.normalize()
posterior
#결과 : 주사위를 굴려 1과 7이 나온 후, 팔면체 주사위의 확률은 약 69%로 가장 높다.
위 결과를 다른 코드로 구현한다.
#위의 작업을 하나의 함수로 적용
def update_dice(pmf, data):
"""Update pmf based on new data."""
hypos = pmf.qs #qs는 분포에 포함되는 원소이다. 주사위 6, 8, 12 이다.
likelihood = 1 / hypos #hypos는 가설이자. 6, 8, 12 이다. 1/6, 1/8, 1/12
impossible = (data > hypos) # True or False
likelihood[impossible] = 0
pmf *= likelihood
pmf.normalize()
#추가설명: x.ps 는 확률이다. x.qs는 원소이다.
# 사전확률
pmf = prior.copy()
pmf
#함수 적용
update_dice(pmf, 1)
update_dice(pmf, 7)
pmf
* Empiricaldist 는 판다스를 기반으로 확률질량함수를 구현할 수 있는 모듈이다.
* 사전확률과 Likelihood, 사후확률을 업데이트 하는데 용이하다.
* 그리고, 사후확률이 업데이트 됨에 따라 해당 가설을 관측(=믿을 수 있는) 사후확률이 가장 높은 MAP를 구할 수 있다.