
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 독후감
- 실무로통하는인과추론
- 회고
- 글또10기
- BigQuery
- 코세라
- 네카라쿠배당토
- 나의서양미술순례
- 인과추론
- 잠재적결과
- DataAnalyst
- 데이터분석가 코딩테스트
- Recsys
- SQL
- Bayesian
- 베이지안통계
- 벡터
- 티스토리챌린지
- 빅쿼리
- 수학적해석학
- 인과추론 무작위 실험
- chatGPT
- recommendation system
- CausalInference
- 선형대수학
- mathematicalthinking
- 데이터분석
- 인과추론개요
- 데이터분석가
- 오블완
- Today
- Total
Derek 의 데이터 분석 성장기
[베이지안] Bayesian - 확률과 베이즈정리 본문
해당 베이지안 공부는 Think Bayes(파이썬을 활용한 베이지안 통계) 책을 기반으로 공부하고, 정리하였습니다.
0. 베이지안
베이지안은 왜 필요할까?
베이지안은 불확실성을 다루는 통계적 방법론 중 하나로, 믿음의 정도를 확률적으로 나타내고 이를 업데이트하는 데 중점을 두는 방법론이다. 빈도주의적 통계학은 데이터의 빈도나 반복에 기반하여 추론을 진행한다.
그렇다면, 빈도주의적 통계학도 있는데 베이지안 접근 방법은 왜 필요할까?
1. 개인화된 추론을 가능케한다.
베이지안 통계학은 개인화된 추론을 허용합니다. 개별의 사전 믿음이나 정보를 고려하여 사후 추정치를 계산할 수 있습니다. 이는 실제 상황에서 많은 가치가 있다고 한다. 예를 들어, 의료 분야에서 각 환자의 고유한 특성과 조건을 고려하여 진단이나 치료에 대한 확률을 계산하는 데 사용될 수 있습니다.
아무래도, 빈도주의는 전체 모수를 기반으로 Mu를 추정하는데에 비해. 베이지안은 각 환자나 가설별로 믿음의 확률을 구하는데 이용되는 것 같다.
2. 불확실성을 명시적으로 다룬다.
베이지안 접근 방식은 불확실성을 명시적으로 다룬다고 한다. 불확실성을 확률 분포로 나타내기 때문에 신뢰도나 확신의 정도를 표현하는 데 효과적이다. 이는 현실 세계에서 우리가 직면하는 많은 문제에 적용할 수 있습니다. 예를 들어, 신약의 효과를 평가하거나 자연재해의 발생 가능성을 예측하는 데에 활용될 수 있다.
3. 새로운 정보의 통합(=업데이트)
베이지안 통계는 새로운 증거가 등장할 때마다 우리의 믿음을 업데이트할 수 있는 구조를 제공한다. 이는 실시간 데이터의 흐름에 따라 결정을 조정할 수 있음을 의미한다.예를 들어, 금융 분야에서 주식 시장의 변동성을 예측하거나, 인공지능 분야에서 기계 학습 모델의 성능을 평가할 때 활용될 여지가 많다고 한다.
1. 확률
조건부 확률 : 조건에 따른 확률이다. A가 일어났을 경우 B가 일어날 확률이다.
EX) 한 응답자가 은행원일때, 이 응답자가 여성일 확률은?
참고로, 조건부 확률은 교환가능 하지 않다. Conjuction(=논리곱 : A and B = B and A) 는 선후가 바뀌어도 동일하지만, 조건부 확률은
2. 베이즈정리

B 가 일어났을 때, A가 일어날 확률을 의미한다. 현재 내가 공부하는 입장에서 베이지안을 이해하기 위한 나의 접근방식은 베이지안은 내 가설(믿음)에 대한. 내 가설이 맞을 확률을 구하는 것이다. 사전확률(Prior) 과 가능도(Likelihood), 증거(Evidence) 를 가지고 내 가설에 대한 사후확률을 업데이트 시키는 것을 의미한다. 업데이트 한다는 것은 사전확률 * 가능도를 곱하여 사후확률(Posterior)를 구하는 과정이다.
그리고, Evidence는 결국 내가 열거한 모든 가설에 대한 정규화를 하기 위해 분모를 취하는 것이다.
그렇다면, 베이즈 정리 및 베이지안은 왜 필요할까? 그것은 관측할 수 있는 증거(Evidence) 혹은 샘플이 충분하지 않을 때 베이지안이 용이하게 작용할 수 있다. 혹은 '몬티홀' 문제 라고 불리는 사전확률이 존재하고, 어떤 사건이 발생했을 때 사후확률이 변동되는 경우에 용이하게 작용한다.
베이즈 이론을 다각도에서 보는 방법은, 통시적 베이즈라고도 부른다. 데이터 일부 D가 주어졌을때, 가설 H의 확률을 갱신하는 방법으로 사용한다는 것. 내가 위에서 접근하는 방식은 통시적 베이즈에 가깝다.
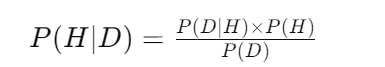
* P(H) 는 데이터를 확인하기 전에 구한 가설의 확률, 사전확률 이다.
* P(H|D) 는 데이터를 확인한 후의 가설 확률, 사후확률이다. = 우리가 알고 싶은 것
* P(D/H)는 가설하에서 해당 데이터가 나올 확률, Likelihood(가능도) 이다.
* P(D) 는 어떤 가설에서든 해당 데이터가 나올 확률로, 데이터의 전체확률이다.
해당 경우에서 P(D)는 만약 가설이 2개라면, P(H1)*P(D|H1) + P(H2)*P(D|H2) 와 같다. 이는 열거된 모든 각 가설에 대한 가능도와 사전확률을 곱한 것들의 합이다.
그리고, 데이터와 사전확률을 사용해서 사후 확률을 구하는 과정을 베이즈 갱신(Bayesian Update) 라고 한다.
4. 베이즈 테이블
베이즈 갱신을 손쉽게 이해하고, 편리하게 할 수 있는 베이즈 테이블이 있다. 판다스를 활용하고, 하나의 예시로 접근해보자.
목적 : 임의의 그릇 2개에서 쿠키를 하나 집었다. 쿠키가 바닐라 였다면(given), 이 쿠키가 1번 그릇에서 나왔을 확률은?
1. 첫번째 그릇(bowl1) 에는 바닐라 쿠키 30개와 초콜릿 쿠키 10개가 들어있다.
2. 두번째 그릇(bowl2) 에는 바닐라 쿠키와 초콜릿 쿠키가 20개씩 들어 있다.
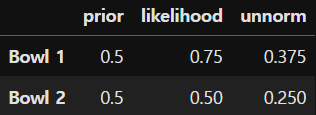
* prior(사전확률) 은 바닐라 쿠키가 그릇1과 2에서 나올 확률은 1/2이다.
* likelihood(가능도)는 각 그릇에서 바닐라 쿠키가 나올 확률이다. P(D|H) = 각 그릇1과 2에서(given) 쿠키가 나올 확률
* unnorm은 두 값의 곱. (이는 표준화되지 않은 사후확률을 의미한다.)
* 그렇다면 필요한 값은? P(D) 이다. 이는 위에서 언급했듯, 각 가설의 사전확률 + 가능도 곱의 합이다.
= P(H1)*P(D|H1) + P(H2)*P(D|H2) => 그리고 0.625이다.

unnorm / 0.625 는 사후확률이다. 즉, 그릇1의 사후확률은 0.6 이다. 그리고 표준화된 사후확률의 합은 1이다. 이 과정을 표준화 혹은 표준화 상수라고도 한다.
베이지안 코드 사후확률 업데이트 코드
def update(table):
"""Compute the posterior probabilities."""
table['unnorm'] = table['prior'] * table['likelihood']
prob_data = table['unnorm'].sum()
table['posterior'] = table['unnorm'] / prob_data
return prob_data
이어서, 위에 언급한 몬티홀 문제를 풀어보자.
*몬티홀은 당신에게 1,2,3 이라고 번호가 붙은 세개의 문을 보여주고, 각 문뒤에 상품이 있다고 한다.
*한 가지 상품은 자동차. 나머지는 염소이다.
*게임의 목적은 3가지 문 중 하나뒤에 있는 자동차를 갖는 것 이다.
그리고, 몬티는 내가 한가지 문을 고르면 그 후에, 염소가 있는 다른 문을 열어준다. 그리고 몬티는 나에게 선택을 고수할지? 아니면 다른 문으로 바꿀 것인지를 묻는다. 여기서 나는 자동차를 얻을 기회를 위해 처음에 한 선택을 고수해야할까? 다른 문으로 바꿔야 할까? 핵심은 어떤 선택이 상품을 얻을 확률을 극대화 하느냐이다
이 게임은 조건이 있다. 몬티는 문을 열고 선택을 바꿀 기회를 준다. 몬티는 내가 고른문이나 자동차가 있는 문을 열지 않는다. 내가 고른 문뒤에 차가 있는 경우에는 나머지 문을 임의로 연다는 가정이다.
결과는 우선, 처음 선택 후에 문을 바꾸는 것이 좋다. 결정을 고수시 1/3(33.3%) 로 차를 갖는다. 하지만, 바꾸면 66.7%로 차를 고를 수 있다. 그 이유를 알아보자!

사전확률은 당연히 1/3 이다. 그리고, 여기서 몬티가 3번 문을 열어 염소를 보여주었다는 관측(=증거, 데이터)를 확보했다. 각 가설하에서 이 데이터의 확률(likelihood) 는 다음과 같이 고려된다.
1. 만약 차가 문 1뒤에 있다면 몬티는 문 2나 3중의 하나를 임의로 고른다. 그리고 몬티가 3번 문을 열 확률은 1/2이다.
2. 만약 차가 문 2뒤에 있다면 몬티는 문 3번을 열었으므로, 이 가설에서 데이터 확률은 1이다.
3. 만약 차가 문 3뒤에 있다면 몬티는 이 문을 열수가 없다. 따라서 이 가설에서 데이터 확률은 0이다.
여기서 2번문의 likelihood가 1인 이유는. 내가 첫번째 선택에서 1번 문을 골랐을 때, 몬티는 1번문을 열어서 보여줄수가 없기 때문이다. 위에서 언급했듯 몬티는 내가 고른문이나 자동차가 있는 문을 열지 않는다. 라는 조건을 위에서 붙였다. 때문에, 다른문에 자동차가 있을 확률이 더 높은 것이다.
'Data > 통계' 카테고리의 다른 글
| [확률론 기초] 확률과 셈(1강 부터 4강까지) (0) | 2024.11.26 |
|---|
