
[Paper] 우버 Dynamic Pricing and Matching 알고리즘 정리
해당 내용은 Uber Tech. 의 Dynamic Pricing and Matching in Ride-Hailing Platforms(2019) 를 참고하였습니다.
- 우버의 매칭과 최적화는 어떻게 이루어질까? -
1. 개요
우버는 사용자와 운전자를 연결짓는 서비스입니다. 개인차량으로 승객을 목적지에 이동 시켜주는 서비스를 기본으로 하나, 확장적으로는 카풀(승객을 여러명 태우는 행위) 또한 가능하게 합니다. 그 외에도, 우버 이츠 등 드라이버가 음식을 배달할 수 있는 서비스까지 가지고 있습니다.
기본적으로 우버는 Ride-Hailing Platform 라는 플랫폼으로서, 사용자가 운반을 요청하면 드라이버(운전자)가 사용자를 픽업하고 목적지에 드랍해주는 플랫폼입니다. 드라이버와 운전자를 매칭 시키는 플랫폼이죠.
그리고, 가격은 수요(승객이 타고 싶어하는 숫자) 와 공급(드라이버의 수) 에 따라 다이나믹하게 변동됩니다. 해당 시스템보다는 저는 어떻게 승객 과 고객 을 효율적으로 매칭시키는 지가 궁금하였습니다. 그래서 오늘은 그 부분에 초점을 맞추려 합니다. (Paper 상으로는 Chapter 2 에 해당 되는 내용) 입니다.

2. 내용
우버의 라이드 형태는 크게 2가지로 나뉩니다. 비공유( 하나의 고객 그룹만 한 차용을 사용 = UberX) 와 공유( 여러 고객 그룹이 서로 다른 픽업 및 하차지점을 가지고 차량을 공유 = UberPool) 이 있습니다.
우버의 비 공유 라이딩은 플랫폼에서 자신의 상태를 Open(호출을 받을 수 있는 상태) 로 변경시 승객을 받을 수 있습니다. 그리고, 이 중 가장 간단한 매칭 방식은 바로 최단 이동 시간 기반 매칭(First-Dispatch ProtocoL) 입니다.
2-1. 최단 이동 시간 기반 매칭
현재 Open(대기) 상태의 드라이버만을 고려하여, 해당 드라이버가 라이더를 픽업하는데 가장 짧은 이동시간을 가지는 드라이버를 선택하여 보내는 방법입니다. 그러나, 해당 방법은 아래(1번과) 같이 최적화 되지 못한 문제점을 가지고 있습니다. 1st(초록색) 승객을 기준으로 해당 승객과 드라이버 중 가장 짧은 이동시간을 가지는 드라이버를 배치시켜보겠습니다.
승객(Rider) 보라색, 파란색 순으로 승객과 차 거리 간의 가장 가까운 드라이버를 배치시켰을 때, 나오는 결과는 아래사진과 같습니다. 3 + 3 + 13 순으로 총 19 라는 Grid 기준으로 19라는 숫자가 나오게 됩니다.
하지만, 만약 바로 위 사진과 같이, 승객과 드라이버를 실시간으로 최단 이동 시간 기반 매칭을 시키지 않는다면 어떨까요? 바로 위 사진은 최적화한 결과입니다. 라이더(승객) 과 드라이버의 정보를 모두 가지고 있다가, 총 거리가 가장 짧아지는 값으로 드라이버와 승객을 배치 한 것 이죠. (1st 파란색 승객은 처음에 3 거리를 가진 드라이버가 아닌, 11 드라이버가 배치 되었습니다)
이와 같이 우버에서는 실시간으로 승객과 드라이버 중 가장 짧은 시간을 배치 시키는 시스템이 효율적이지 않다고 판단했습니다.(물론 경우에 따라 다를 수 있습니다)
이를 해결하고자, 우버에서는 이를 최적화 하고자 하는 방식을 택했습니다. 최적화를 위해 우버는 일단 몇가지 제약조건을 만들었습니다.
1. 최대배차반경(MDR : Maximum Dispatch Radius) = 드라이버가 너무 먼 거리에 있는 라이더와 매칭되지 않도록 하는 제한 방식.
위 제약식을 시작으로, 우버는 평균 라이더 대기 시간이 너무 길어지지 않도록 만들었습니다. 최적화 한다고 라이더가 드라이버를 몇날며칠을 기다릴 순 없으니깐요!. 그리고 우버는 배치 기반 매칭(Batch Matching) 시스템을 도입하였습니다.
2-2. 배치 기반 매칭(Batch Matching)
배치 기반 매칭은 매칭을 즉각적으로 수행하는 대신, 요청(Request)를 몇 초 동안 모아 두었다가 일괄적으로 최적의 배차를 수행하는 방식입니다.
1. 짧은 시간 동안 배차 요청을 모음(i.e : 3~5초)
2. 배치된 요청 그룹에 대해 최적화 문제를 해겨하여 매칭을 수행
3. 매칭되지 않은 요청은 다음 배칭 윈도우(batch window)로 이월
하는 방식입니다.
배치 기반 매칭의 장점은
1. 더 나은 매칭 기회 -> 더 많은 라이더와 드라이버를 고려할 수 있어 최적의 매칭 가능
2. 대기 시간 단축 -> 첫 번째로 매칭된 드라이버보다 더 가까운 드라이버와 매칭될 확률 증가
3. 연구 결과, 배치기반 매칭이 즉각 매칭(First Dispatch Protocol) 보다 성능이 뛰어나다는 성과평가를 가졌다고 합니다.
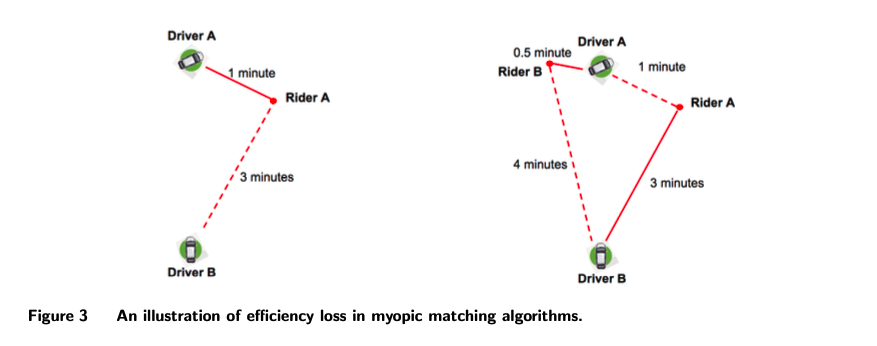
이와 같은 접근 방식을 갖는 이유는 아래 사진과 같이, 새로운 라이더의 요청이 발생했을 시 Driver A 와 Rider A를 매칭 시키는게 아니라, 큐를 쌓아두었다가 Driver A와 Rider B를 매칭 시키는것이 훨씬 더 거리기반으로 이득이기 때문입니다.
Q. 그렇다면, 우버는 짧은 시간 동안 배차 요청을 모음 시간을 어떻게 설정 했을까요?
배치 기반 매칭에서 배차 요청을 모으는 시간(배칭 윈도우)는 너무 길거나 짧으면 비효율적이므로, 확률적 모델을 활용하여 최적의 배칭 시간을 결정하는 노하우를 이용했습니다.

이를 통해, 라이더(승객)의 요청 모음 시간을 최적화 하는 방법을 구현했습니다.
시간을 최적화 했다면, 그 밖의 라이더와 드라이버라는 수요와 공급은 어떻게 최적화 했을까요?
2-3. 최적화
이는 최대 이진 그래프 매칭(Bipartite Graph Matching) 문제로 모델링 됩니다.

와 같은 방법을 사용했습니다. 그중, 우버는 선형 프로그래밍 LP(Linear Programming) 의 Relxation(근사,이완) 기법을 사용하여 연속 변수로 변환 후, 빠르게 최적화 해를 근사하는 방법을 사용했습니다.
여러 최적화 방법을 고민했다고 합니다. 하지만, integer(이진 정수 프로그래밍)은 NP-hard 문제가 존재, 헝가리안 알고리즘 같은 작은 규모 배칭 문제의 한계점을 해결하고자 이 방법을 채택했다고 하네요.
조금더 자세히 설명하자면 우버의 이진 정수 최적화 문제는 아래와 같습니다.


이와 같이 문제를 해결했다고 하네요.
Q. 이진 정수 최적화를 선형 프로그래밍으로 변환하는 Relaxation(근사,이완) 기법은 무엇인가? 링크




ChatGPT가 제 정리보다 훨씬 나아서,, 위와 같이 첨부해보았습니다!
결론적으로 우버는 LP 최적화 문제를 모델링하고 이진 변수를 연속 변수로 변환하는 Relaxation 최적화 기법을 채택하였는데요. 이는, 빠르게 실시간으로 수천만 건의 매칭을 처리하는 우버 플랫폼에 맞게, 빠르게 근사해를 구할 수 있기 때문에 채택한 것으로 보여집니다.
2-4. 동적 매칭(Dynamic Matching)
위와 같이 최적화를 달성했지만, 우버는 보다 더 좋은 모델링을 위해 동적 매칭방법을 적용했습니다. 이는 '예측' 을 적용하는 것 인데요. 배치 기반 매칭과 다르게, 동적매칭은 미래의 수요 및 공급을 예측하여 최적의 매칭을 결정하는 방식 입니다.
동적 매칭의 핵심 아이디어는 미래의 라이더 및 드라이버 패턴을 예측하여 현재 매칭을 보류하는 것이 더 나을 수 있다는 아이디어 입니다. 예로, 현재 라이더 A를 드라이버 B와 매칭할 수도 있지만, 다음 배치 윈도우에서 더 좋은 매칭이 생길수도 있다는 가설을 가지고 접근하는 방식입니다.
예측을 하기 위해서 다양한 예측 모델을 결합하여 최적의 매칭을 수행했다고 하네요.
1. 회귀(RF, Xgboost, 신경망) 등의 모델링을 활용하여 날씨, 이벤트, 요일, 시간대 등 다양한 변수를 고려하여 예측을 수행했다고 합니다.

2. 심층 강화학습(Deep Reinforcement Learning) 의 Multi-Agent Reinforcement Learning(MARL) 기법을 활용하여 실시간 공급- 수요를 예측했다 합니다. 예로, 우버는 수요가 몰릴 지역(공연장, 경기장, 기차역) 등을 실시간으로 예측하여 드라이버를 미리 배치 하는 방식을 채택했다고 합니다.

3. 그래프 기반 최적화(Graph-Based Optimization) 으로 도로 네트워크를 그래프로 모델링하여, 최적 경로 및 수요를 예측했다고 합니다. 예로, GNN을 사용하여 각 노드(지역)의 향후 수요 변화 예측을 했다고 합니다.

이와 같은 방식이 효과적인 이유는 장기적 패턴 분석(날씨) + 실시간 최적화 + 도로 네트워크 상태를 결합하기 위해 사용했다고 하네요. 또한, 단일 모델의 한계를 극복하며 모델 특성별 보안점을 강화하기 위해 사용했다고 합니다.
Q. 동적매칭으로 미래 수요를 예측했을 때, 이를 실시간 수요와 어떻게 연결지어 최적화 모델링을 했을까?




이와 같이 예측을 기반으로 미리 배치, 가격을 재조정, 실시간으로 배차를 최적화해서 고객 경험과 효율성을 늘리는 방법을 고안했습니다.
3. 결론
우버의 매칭 시스템은 수요와 공급의 실시간성을 반영한 최적화 모델입니다.
매칭 방식은 배치 기반 매칭과 동적 매칭으로 나뉘어 집니다. 배치 기반 매칭에서는 선형 프로그래밍(LP)과 이완=근사(Relaxation) 기법을 활용해 빠르고 효율적으로 드라이버와 라이더를 연결합니다.
또한, 동적 매칭에서는 머신러닝 기반 수요-공급 예측으로 효율적인 최적화 모델링을 하고 있습니다.
XGBoost 같은 회귀 모델로 장기적인 패턴을 분석하고, 강화 학습(DDPG, MARL)을 통해 실시간으로 최적의 드라이버 배치를 결정합니다.
여기에 그래프 신경망(GNN)을 적용해 도로 네트워크를 분석하고 최적의 이동 경로를 추천합니다. 이를 통해 대기 시간은 최소화하고, 드라이버와 라이더의 유저 경험도 저해시키지 않으며 본인들의 매출을 극대화 할 수 있는 방법을 고안했습니다.
개인적으로, 우버라는 플랫폼이 고려해야할 사항이 정말 많겠구나 라고 느낀 논문이자 글이였습니다. 드라이버와 라이더를 매칭 시키는 문제를 해결하기 위해 최고의 효율적인 방법을 고안하고 있구나라고 느꼈습니다. 2018년도에 나온 논문이니, 지금은 더 고도화 됐겠죠?
또한, 단순 라이더 - 드라이버 매칭의 일부문서인데 이것말고도 가격조정과 우버이츠, CarPool(쉐어) 까지 고려한다면 더 많은 차원이 생길 것 같아서 머리 터지겠구나. 라고 느꼈던 논문입니다! 오늘은 우버의 매칭 시스템을 알아보았습니다!