[실무로 통하는 인과추론] 6. 이질적 처치 효과
1. 개요
인과추론을 추정할 때, 대부분 평균 처치 효과인 ATE를 계산했다. 그러나, 처치 효과는 개인에게 적용시 각기 다른 효과를 가져올 수 있다.
처치(Treatment) 가 개인(Individual) 별로 다른 영향도를 갖기 때문에, 그 영향도 값을 추정하는 것. 그것이 바로 이질적 처치효과이다.
예를 들어, 어떤 고객에게는 할인 쿠폰을 주면 유익하지만, 다른 고객에게는 그렇지 않을 수 있다. 할인에 대한 민감한 고객군이 있기 때문이다. 혹은 백신 접종도 어떤 환자에게는 더 효과적으로 작용할 수 있다. 때문에 백신으로 인한 영향도가 큰 환자에게 백신을 먼저 제공하는 방법. 이러한 상황에서 개인화가 핵심이자, 이 개인화를 위한 한 가지 방법이 바로 이질적 효과를 고려해서 조건부 평균 처치효과(CATE)를 추정하는 것 이다.
그리고, 이를 구현하기 위해선 세분화(Segment)를 통해 고객군을 나누는 것이 중요하다. 세그먼트 별로 다른 효과를 추정 하는 것 또한 중요하다.
머신러닝 관점에서는 변수 X를 통해 Y를 예측한다. 이는 y축에 따라 공간을 분할하게 되며, 예측 모델이 목표를 잘 근사한 것이라 가정한다. 그러나, 이 방법으로는 처치효과가 다른 그룹들을 찾을 수가 없다.
인과추론 관점에서는 결과 대신 개인별로 효과값을 추정해야 한다. 아래와 같은 도함수를 통해 Treatment 가 가해졌을 때, Y의 값인 '변화율' 인 도함수를 관측하는 것 이다.
2. CATE 구하기
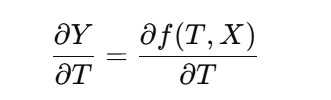
그리고, 이 도함수(변화율) 을 통해 CATE 값을 예측하는 방법은 아래와 같습니다.
import statsmodels.formula.api as smf
X = ["C(month)", "C(weekday)", "is_holiday", "competitors_price"]
regr_cate = smf.ols(f"sales ~ discounts*({'+'.join(X)})",
data=data).fit()
우선, 통제변수(공변량)을 통해 Y 값을 예측합니다. 그러나, 우리의 관심사는 변화율(변화량) 이죠. 교재에서는 아래와 같은 방식으로 변화량(변화율)을 도출합니다. 그리고, + join으로 교호작용까지 포함한 회귀식을 구합니다.
1. 원본 데이터를 그대로 사용한 예측
2. 원본 데이터를 사용하지만 처치를 한 단위씩 증가시킨 예측. 이 두 예측값의 차이가 CATE 예측값이 된다.
ols_cate_pred = (
regr_cate.predict(data.assign(discounts=data["discounts"]+1))
-regr_cate.predict(data)
)
위의 코드를 보면, discount인 원본 데이터에 +1 를 하여, 한단위 증가시키고 그 차이를 구합니다. 이 두 예측값의 차이가 CATE의 예측값을 구하는 방식입니다. 그러나, 의문점은 이 모델의 성능입니다. 실제 처치효과가 개별 수준에서 관측되지 않기 때문에 실젯 값과 예측값을 비교하는 것이 불가능하기 때문이죠.
2-2. CATE 예측 평가하기
CATE 예측은 일반 머신러닝 예측과 유사하지만, 처치효과의 개인별 차이를 추정하는 것이 목표이다. 교차 검증과 같은 기본 머신러닝 평가 방법을 적용할 수 있지만 약간의 조정이 필요하다.
이를 위해선, 데이터를 기존 회귀(만약, 데이터가 시점에 따른 예측같은 시계열 회귀 방식일 경우)는 데이터셋을 훈련과 테스트를 위한 방식으로 분할하는 것이 이 CATE 모델의 성능을 평가하는 방법이 될 수 있다.
train = data.query("day<'2018-01-01'")
test = data.query("day>='2018-01-01'")
#훈련
X = ["C(month)", "C(weekday)", "is_holiday", "competitors_price"]
regr_model = smf.ols(f"sales ~ discounts*({'+'.join(X)})",
data=train).fit()
#테스트 : +1 - Original
cate_pred = (
regr_model.predict(test.assign(discounts=test["discounts"]+1))
-regr_model.predict(test)
)
그리고 위와 같이 Train 을 통한 훈련, Test를 가지고 예측한 결과에 +1을 더한 것과 아닌 것의 차이로 CATE 를 구한다.
(이어서..)