[실무로 통하는 인과추론] 1장 : 인과추론 소개

해당 글은 모두 실무로 통하는 인과추론을 기반으로 작성, 자료를 참고 하였음을 밝힙니다.
1-1. 인과추론 개념
연관관계는 인과관계가 아니다. 연관관계를 인과관계로 오해하여 잘못된 의사결정을 내릴수도 있다. 만약, 한 국가의 노벨상 수상자 수를 1인당 초콜릿 소비량의 증감으로 생각해보자. 증감의 상관도(=연관관계) 가 있다고 판단할 수 있지만, 올바른 해석일까?
연관관계는 두개의 확률변수 X와 Y 가 같이 증가하거나 감소하는 것이다.
그러나, 인과관계는 X가 Y의 원인이 되는 것과 같다.
인과추론은 연관관계로부터 인과관계를 추론하고, 언제 그리고 왜 서로 다른지 이해하는 과학적 접근이다.
1-2. 머신러닝과 인과추론
그렇다면, 머신러닝을 활용해서 인과관계를 파악하면 안될까? 라고 생각한다. 하지만, ML은 지능의 주요 구성인 예측을 하는데 탁월하다.
연관도를 파악하는데는 도움이 될 수 있지만, ML은 만병통치약이 될순 없다. 예를 들어, 호텔 업계에서 비성수기에는 숙바 요금이 낮고, 수요가 가장 많고 호텔이 만실인 성수기에는 요금이 높다. 해당 데이터를 바탕으로 모델링 하면, 모델은 가격을 올리면 더 많은 객실이 판매될 것이라는 나이브 한 예측할 가능성이 있다.
확률변수 X를 통해 Y를 예측할 순 있으나, X가 Y의 원인이라 생각하기엔 어려울 수 있다는 관점이다.
1-3. 처치(Treatment)와 결과(Outcome)
장난감 할인 데이터와 함께 그렇다면 연관도와 인과관계와 친숙해져 보자.
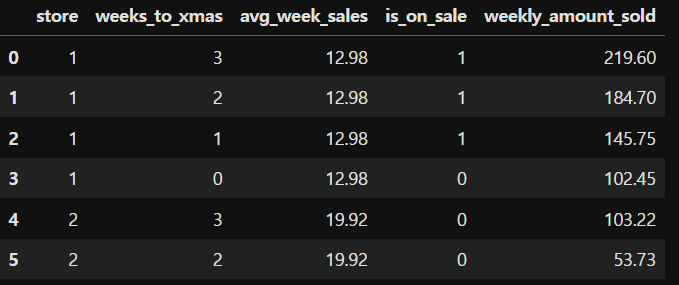
store는 상점이고, xmas(크리스마스) 직전 주차에 장난감 할인(is_on_sale) 을 하면 상점 주간 판매량(weekly_amount_sale) 에 도움이 될까? 라는 예시입니다.
여기서 인과추론에서 말하는 T(Treatment) 라는 단어가 나오게 됩니다. 여기서 말하는 Treatment 는 알고 싶은 인과의 효과를 의미합니다. 예를 들어, 장난감 할인이 실제 판매량에 영향을 미쳤는가? 라고 생각하면 됩니다.
그리고,
Ti = 1 : 실험대상 i가 Treatment 를 받은 경우
Ti = 0 : 실험대상 i가 Treatment 를 받지 않은 경우
로 Treatment 의 효과와 변수간의 인과 관계를 파악하곤 합니다.
또한, 우리가 알고 싶은 매출인 Y(outcome) 결과는 주로 Yi 로 표기가 됩니다. T라는 처치와 Y라는 결과 두 개념을 활용하여 할인여부와 주간 판매량 사이의 영향도를 파악할 수 있는 것 입니다. 그리고, 위와 같은 수식으로 표현하는 것이고요.
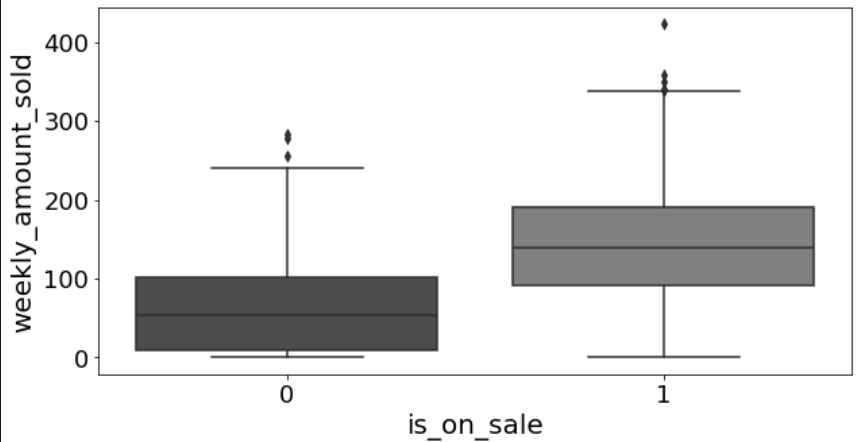
시각적으로 판단하면, 할인 시 주간 판매량이 더 높다. 그러나, 판매량만이 과연 주간 판매량에 영향을 주었을까? 할인을 진행하는 상점이 대기업이라 더 공격적으로 마케팅을 진행할 수 있었다면? 혹은 원래부터 잘 되었는데 해당 12월에만 할인을 진행해서 더 높은 판매량을 기록한 것 일 수도 있다.
때문에, 할인의 순수한 효과를 알고 싶다면 우리는 과거로 회귀 해서 '동일한 상점(실험대상)' 을 대상으로 할인을 진행해보지 않아야 한다. store 1이 만약 할인을 진행하지 않았더라면? 이라는 상상력을 발휘해서 할인을 진행한 결과와 비교해서 Treatment(할인) 효과를 파악할 수 있어야 한다.
이것이 인과추론에서 말하는 반사실(CounterFactual) 이며 두 상황을 비교함으로서 치료의 효과를 파악해야 한다.
그러나, 현실에서는 과거로 돌아가는 것이 불가하다. 때문에, 다른 방법을 찾아야 한다.
1-4. 인과모델
인과추론을 공부하는데 있어 직관적 사고력도 도움이 되지만, 공식 표기법들이 존재하고 공용어로서 사용되긴 합니다.
인과모델은 화살표(<-) 로 표시하는 메커니즘이 있습니다.
위 데이터 도표에서 본 것처럼 우리는 순수하게 IsOnSale(할인) 이 주간 판매량에 미치는 영향력을 알고 싶습니다. 하지만, 상상력을 발휘한 것 처럼 대기업이나 상점이 대기업 프랜차이즈 일 경우 그 영향도는 달라질 수 있습니다. 하지만, 우리는 이와 같은 예시가 영향도를 미칠 수 있겠다고 생각했습니다.
그리고, 여기서 내생변수(endogenous variable) 개념이 나오게 됩니다. 원서에서는 모델링하지 않은 변수를 외생변수라 정의했지만, 이 책에서는 내생변수라고 설명했습니다.
내생변수는 모델에 포함된 변수(예측 모델 혹은 인과 모델)로는 아직 설명 되지 않은, 그러나 변수의 모든 변동을 포함시키는 것을 의미한다고 합니다. 우리가 가진 데이터로 표현하자면, 상점 규모 크기(Business Size) 및 관측되지 않았으나 매출에 영향을 줄 수 있는 모든 변수들을 의미한다고 생각하면 될 것 같습니다.
그리고, 이를 수식화 하면 이와 같습니다. 어떤 function(f)가 존재하고 function 마다 존재하는 u(내생변수)가 존재합니다. 그, 내생변수는 각각 <- 의 Y(결과)에 영향을 미치는 것 입니다.
Business Size <- f1(u1)
IsOnSale <- f2(Business Size, u2)
AmountSold <- f3(IsOnsale, BusinessSize, u3)
Business Size는 f1이라는 함수를 통해 u1이라는 관측되지 않은 모든 결과에 의해 모델링 된다. 그리고, 최종 amountsold 매출은 위의 할인여부, business size와 u3 라는 모든 변수를 통해 인과모델을 구축한다. 라고 해석할 수 있을 것 같습니다.
AmountSold_i = a + (B_1 * IsOnsale_i) + (B_2 * Business Size_i) + e_i
앞에서 정의한 화살표 인과모델은 궁극적으로 위와 같은 수식으로 선형모델로 정의할 수 있습니다. 각각의 변수의 영향도가 존재하고 우리가 관측할 수 없는 error term(e_i) 의 합으로 정의 한다. 인과모델을 선형모델로 표현한 것이라 생각하면 직관적으로 이해할 수 있습니다.
1-4-1. 개입(Intervention)
인과모델에는 개입(Intervention) 이라는 용어가 존재합니다. What IF(만약에 내가 그 효과를 안줬으면?) 를 생각하면 좋습니다.
우리는 이미 할인을 적용했지만, 과거로 돌아가서 할인을 주지 않는다면 매출에 어떤 영향력을 줬을까? 입니다. 인과추론에서는 do(.) 연산자를 활용해서 이 표현을 나타냅니다. do(T= t_0) 으로 표현합니다. do 한다. T_0 할인효과를 적용하지 않는다. 라고 생각하면 이해가 될 것 같습니다!
반대로, do(T=t_1)은 할인을 하지 않은 회사에 T_1 할인효과를 적용하면 결과는 어떨까? 라는 수식을 의미합니다. do 연산자는 관측된 데이터에서 얻을 수 없는 인과추정량을 정의하는데 사용됩니다. 하지만, 인과추정량을 표현하는데 사용되는 이론적 개념으로 매우 유용합니다.
그리고, 인과추론은 인과 추정량에 대한 이론적 표현에서 직접 관측할 수 없는 부분을 제거하기 위한 일련의 과정으로, 이를 식별(identifaction)이라고 부릅니다.
1-4-2. 개별 처치효과(ITE)
위의 do(.) 연산자를 사용하면 개별 실험 대상(i) 에 처치가 결과에 미치는 영향인 개별 처치효과(Individual treatment effect) ITE를 표현할 수 있습니다.
t_i = Y_i | do(T = t_1) - Y_i | do(T = t_0)
모든 store에 할인을 한 효과와 할인을 하지 않은 결과의 차이를 구한다면, 이는 순수한 Treatment의 효과를 각 개별에 대해 얻을 수 있다. 그리고 이는 Intervention(개입)의 효과이다. 이론적으로 해당 표현으로 인과효과를 구할 수 있지만 반드시 데이터에서 이 효과를 찾을 수 있는 것은 아닙니다.
1-4-3. 잠재적 결과(Potential Outcome)
do(.) 연산자와 함께 인과추론에서 가장 흥미롭고 널리 사용되는 개념인 반사실 또는 잠재적 결과(potential Outcome) 도 수식으로 정의할 수 있습니다.
Y_ti = Y_i | do(T_i = t)
처치가 t 인 상태일 때, 실험대상 i의 결과는 Y가 될 것이다를 의미합니다. 다른 수식으론 Y_ti = Y(t)_i 로 의미합니다.
Y_i = { Y_1i : 실험대상 i가 처치받은 잠재적 결과
{Y_0i : 같은대상 i가 처치받지 않은 잠재적 결과
즉, 같은 대상을 통해 실제적으로 얻을 수 있는 사실적 결과(factual outcome) 와 관측할 수 없는 반사실적 결과(counter factual outcome)을 지칭 하는 것 입니다.
뭔가.. 점점 새로운 용어가 나오면서 복잡해지는 것 같지만 쉽게 이해하자면 그냥 관측하지 못한 결과에 대해 만약 관측했다면 어떤 인과효과가 있을까? 와 실제로 관측한 결과를 가지고 Treatment 효과 여부에 따라 그 효과를 개별에 따라 차이를 구하는 것 입니다. 인과추론에는 가정(assumption)이 동반됩니다.
그리고, 이 가정에는 일치성이 적용됩니다. 일치성이란 할인의 효과는 1번 적용되는 것이 원칙이다. 같은 개인(individual)이 여러번 할인 효과를 적용 받았다고 가정한다면 이는 일치성 위배이다. 라는 것 입니다.
두번째 가정에는 상호간섭 없음(SUTVA)가 적용됩니다. 하나의 실험 대상에 대한 효과는 다른 실험 대상의 영향을 받지 않는다. 라는 것 입니다. A/B Test로 가정하자면 고객 한 명은 두 가지 실험에 같이 노출 될 경우 그 효과는 하나의 Treatment Effect를 측정하기 어려울 수 있습니다.
1-4-4. 인과 추정량과 평균 처치효과(ATE)
인과추론의 잠재적 개념과 가정을 알게 되었지만, 현실적으로 잠재적 결과 중 하나만 우리는 관측할 수 있으므로 개별 처치 효과를 알 수 없습니다.
비록 개별 효과 t_i 는 알 수 없지만 데이터에서 학습할 수 있는 세 가지 인과 추정량에 대해 알아보려 합니다.
1. 평균 처치 효과(average treatment effect) 를 알아보려 합니다.
1-1. ATE = E[t_i] : 개별효과를 통해 얻은 평균 처치 효과
1-2. ATE = E[Y_1i - Y0i] : 치료를 받은 결과와 치료를 받지 않은 개별 효과의 차이 평균
1-3. ATE = E[Y | do(T=1)] - E[Y | do(T=0)] : 만약 모든 개별에게 효과를 가했을때와 모든 개별에게 효과를 가하지 않았을때의 차이 평균
즉, 평균 처치 효과는 처치 T가 평균적으로 미치는 영향력을 의미합니다. ATE 또한 현실적으로 없는 데이터에 대한 가정하기 때문에 직접적으론 알 수 없습니다. 하지만, 추정할 수 있습니다.
2. 실험군에 대한 평균 처치 효과(ATT) = (average treatment effect on the treated) 를 알아보려 합니다.
수식은 이와 같이 정의 됩니다. ATT = E[Y_1i - Y_0i | T= 1]
이는 처치 받은 대상에 대한 처치 효과를 의미합니다. 한 도시에서 진행한 오프라인 마켓팅 캠페인으로 해당 도시에서 얼마나 많은 추가 고객을 모객했는지 알고 싶다고 가정 할 때, 마케팅 캠페인이 진행한 도시에 대한 마케팅 효과가 ATT 입니다. 동일한 처치에 대해 두 가지 잠재적 결과에 대해 설명하고 있습니다. ATT 는 처치받은 대상을 조건으로 하므로 Y_0i 는 항상 관측되진 않지만, 이론적으론 이와 같습니다.
3. 조건부 평균 처치 효과(CATE) = (conditional average treatment effect) 를 알아보려 합니다.
CATE = E[Y_1i - Y_0i | X = x]
이는 변수 X로 정의된 그룹에서의 처치 효과 입니다. 예로, 이메일이 45세 이상의 고객과 아닌 대상에 대해 미치는 영향력을 알고 싶을 때, 조건부로 어떤 그룹에서 영향력을 미치는지를 아는 방법입니다.

그럼, 이번엔 위에서 정의한 수식들 을 가지고 한 번 데이터를 만들어 보겠습니다. i는 각각 indivifual을 의미. y는 outcome y0과 y1에 대한 잠재적 결과를 의미합니다. t는 처치 여부, x는 크리스마스까지의 시간을 표시하는 공변량. 할인여부는 t 이고. 판매량은 결국 y 입니다. 그리고 조건부 cate를 위해선 x = 1(이는 크리스마스 전 1주)를 의미 등으로 수식을 표현할 수 있고, 이를 조건부를 걸 수 있습니다. te는 잠재적 결과에 대한 effect 를 의미합니다.
위의 데이터를 통해 우리가 정한 수식을 접근 할 수 있습니다. 하지만? 현실은 아래와 같이 관측할 수 없는 Potential Outcome 들은 모두 Null 처리 되어 있죠. ㅠ_ㅠ

때문에, 인과관계를 밝히는 것은 가정을 통해 접근했을 때는 쉽지 않기도 합니다.
1-5. 편향(Bias)
편향은 인과관계와 연과관계를 다르게 만드는 요소 입니다. 편향은 데이터에서 추정하는 수치가 찾으려는 인과 추정량과 일치하지 않는다는 사실 때문입니다.
수식으로 접근하자면 ATE = E[Y_0 | T = 1] 은 실험군이 처치 받지 않았을 경우와 E[Y_1 | T= 0] 인 대조군이 처치 받았을 경우를 추정해야 합니다. 실험군과 대조군의 평균 결과를 비교할 때, 기본적으로 E[Y_1 | T = 0]을 사용하여 E[Y_0]을 추정하고, E[Y | T = 1] 을 사용하여 E[Y_1]을 추정합니다. 즉 E[Y_t]를 찾을 때, E[Y|T= t] 를 추정하게 됩니다. 두값이 일치하지 않는다면, 처치 t를 받은 실험 대상의 평균 결과인 E[Y|T = t]를 추정하고 싶은 E[Y_t]의 편향 추정량이 됩니다.
그렇다면, 편향은 왜 발생할까요? 위의 스토어로 예시를 들자면, 할인에 상관없이 Store 1을 선호하는 고객들(=대기업 제품 선호) 하는 영향이 있을수도 있기 때문입니다.
혹시 Selection Bias 란 말을 들어보신 적 있으실까요? 선택편향이란 용어로 사용되는데요. 이는 Treatment(할인)에 상관없이 고객들이 직접 선택하는 Bias 가 있어 해당 store1을 더 선호하는 경향이 있기 때문이라고도 설명할 수 있습니다.
편향을 없애는 결과를 관측할 수 있는 조건은 결국 실험군과 대조군이 서로 교환 가능하다면(위 예시에서는 대기업이라 했지만, 다른 대조군도 대기업이라면 혹은 다른 조건들이 비슷하다면) 간단하게 연과관계가 인과관계가 됨을 알 수 있습니다.
다른 식으로 해석하자며, 잠재적 결과(치료 받았다면 혹은 안받았더라면 등) 이 둘의 결과가 모두 같을 때도 편향을 없애고 독립성 가정을 얻을 수 있다고 말합니다.
1-6. 랜덤화와 식별
위와 같은 편향 효과를 없애는 것은 랜덤화 라는 무작위 기법으로 해결할 수 있습니다. 할인을 적용하는 기업 a를 대기업이 만이 하는 것이 아니라, 1번 부터 6번까지의 store(기업 b가 포함된 곳에도) 무작위로 할인을 적용하고 기업 a는 무작위로 적용을 하지 않는 다는 등.
A/B test 에서도 실험군과 대조군을 무작위로 모수를 추출하여 적용하고 나누는 것과 같은 것 입니다. 이럴 때 기존의 편향을 최대한 제거하고 동등하게 인과효과를 파악할 수 있음을 말하고 있습니다.
1-7. 정리
1장에서는 Potential Outcome(잠재적 결과) 라는 실험대상이 만약 Treatment를 받지 않았더라면 관측할 수 있는 잠재적 결과를 배웠습니다. 잠재적 결과는 연과관계와 인과관계가 다른 이유를 이해하는데 유용합니다. 즉, 실험군과 대조군이 처치 이외의 이유 때문에 서로 다르다면 두 그룹간의 비교시 실제 인과효과가 아닌 편향된(Bias) 추정 값이 산출됩니다.
그리고, 인과관계와 연관관계가 같아 질려면 실험군과 대조군이 교환(비교) 가능하거나(=Treatment 이외의 모든 조건이 거의 비슷) 혹은 Treatment를 무작위로 배정한 경우에 처치 효과를 알 수 있다고 합니다.
그리고, 한 실험대상의 처치가 다른 대상의 결과에 영향을 미치지 않아야 함(SUTVA) 를 고려합니다.
1장에서는 인과추론과 관련된 다양한 용어가 나옵니다. 처음 접하는 단어가 많지만, 최대한 서술식으로 풀며 저도 이해하려 노력했습니다.
질문과 정정은 언제나 환영입니다.
* 참고 : 실무로 통화는 인과추론 with Python 교재
* 또한, 개인적으론 인과추론 공부 2회차 입니다! 이번엔 교재를 완독하는 것을 목표로 합니다 :)